
Machine Learning for Trading
Built a stock trading agent that used a re-inforcement learner-based approach, using Q-Learner to learn the best policy and trade automatically.
The learner was trained on certain popular Technical Indicators of a stock. Below are some details on the project.
Objective:
Develop a learning trading agent using a reinforcement learner-based approach.
Approach:
A learning problem based on Markov Decision Process needs States, Rewards and Actions.
States:
For the states, we formulated the problem in such a way, that the state of the world on any given day was a single number representing the value of various indicators. This was done by calculating each indicator individually, and then discretizing them.
Rewards:
Any action from the learner, results in a reward for the learner, and a new updated state. This is essentially a feedback to the learner, based on it’s last action. The rewards function for the learner is based on the total daily change in portfolio value every day.
Actions:
The learner was initialized with an option to choose amongst 3 actions (Number 0,1,2). These 3 actions were not explicitly defined for the learner, but the learner learns from the reward function what each action does. Thus, the 3 actions (Long, Short, Hold) are given as feedback to the learner in the form of an update in the state space number, as well as the corresponding reward associated with it. The learner learns a policy based on this, to provide an appropriate action to maximize returns.
Result:
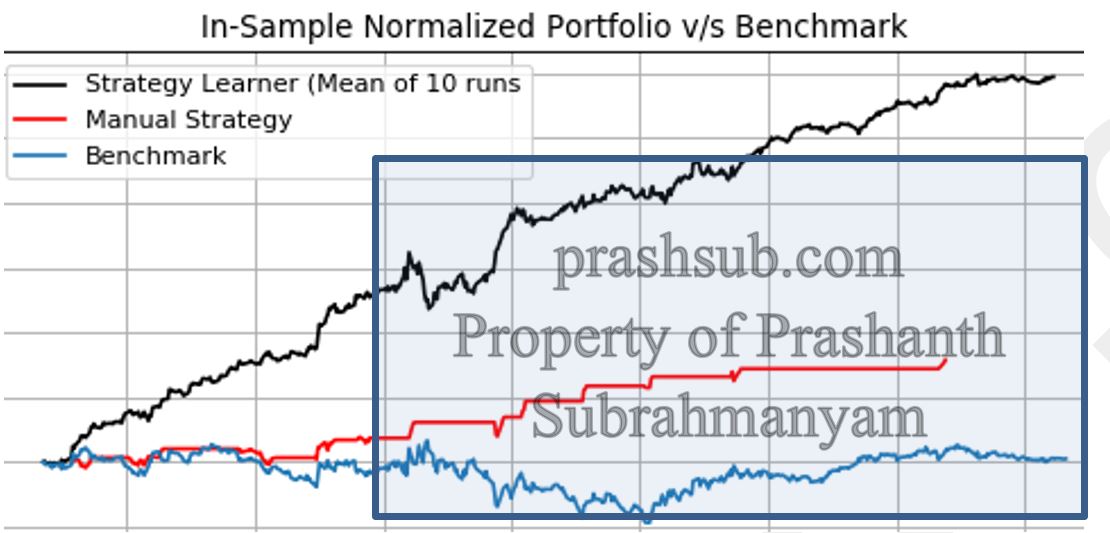
In the in-sample period, the strategy learner consistently beat the Manual Strategy by an approximate margin of 100%. It also beat the benchmark by a margin of 150%. This performance is shown below.
The performance of the strategy learner shown, is a mean of the strategy learner performance over 10 individual runs. This shows the consistency of the strategy learner performance. Although, there may be some variation in each run of the strategy learner, owing the randomness built into the Q-Learner, the mean performance is bounded within at least about 150% of the original portfolio value consistently.
Code and report available on request.
Comments